- Active Learning –
A technique in machine learning where models interactively query a user or information source to label new data points, enhancing learning efficiency. It involves selecting the most informative data points for labeling, querying an expert for annotations, and updating the model with this new information. This approach reduces the need for large labeled datasets by focusing on the most valuable examples for improving model accuracy. Active Learning is especially useful when labeled data is scarce or costly, optimizing both the learning process and resource utilization.
- Affinity Propagation –
In statistics and data mining, affinity propagation (AP) is a clustering algorithm based on the concept of “message passing” between data points. Unlike clustering algorithms such as k-means or k-medoids, affinity propagation does not require the number of clusters to be determined or estimated before running the algorithm. Similar to k-medoids, affinity propagation finds “exemplars”, members of the input set that are representative of clusters.
- Agents –
Utilizing a language model as a reasoning engine, agents integrate with two primary components: tools and memory. This concept involves leveraging language models to facilitate reasoning tasks, where agents serve as intermediaries connecting these models with tools for processing and memory for retaining information. By harnessing the capabilities of language models, agents enhance reasoning capabilities in various applications, enabling tasks such as decision-making, problem-solving, and information retrieval. This framework underscores the role of language models in augmenting cognitive processes and enabling intelligent interactions between humans and machines.
- AI Agent –
Autonomous system (or program) that perceives its environment through sensors (or data sources), processes information using algorithms (or models), and takes actions to achieve specific goals. We can think of an AI agent as an LLM with access to external tools. It runs in a loop, deciding how to behave and what tools to use at each iteration.
- Autoformalism –
A branch of research that involves using automation such as AI/LLMs to generate formal mathematical proofs. The field is primarily focused on doing this for actual math problems/papers, but it feels very adjacent to us especially if you take the view that legal documents are computer programs that happen to be written in natural language.
- Axiom –
In artificial intelligence (AI), an axiom is a rule or principle that is accepted as true because it is self-evident or useful, but cannot be proven. For example, “supply equals demand” is an Axiom.
- Backpropagation –
A fundamental algorithm in neural network training, serving to fine-tune the weights of the network to minimize errors. It operates by calculating the gradient of the loss function (which measures the difference between the predicted and actual outputs) with respect to each weight in the network, using the chain rule of calculus. This process involves two main phases: a forward pass, where input data is passed through the network to obtain a prediction, and a backward pass, where gradients are propagated back through the network to update the weights. This iterative adjustment of weights allows the network to learn from the data, improving its accuracy over time. Backpropagation is crucial for the development of deep learning models, enabling them to learn complex patterns in large datasets.
- BERT –
Bidirectional Encoder Representations from Transformers (BERT), introduced by Google in 2018, revolutionized natural language processing (NLP). As a deeply bidirectional model, BERT captures the context of a word based on all of its surroundings (both left and right of the word), unlike previous models that viewed the text unidirectionally. This model is pre-trained on a vast corpus of plain text (such as Wikipedia) without specific task-oriented training data, making it unsupervised. BERT’s pre-training involves understanding the relationships between sentences and the context of words within them. Once pre-trained, BERT can be fine-tuned with additional data for a wide range of NLP tasks like question answering, sentiment analysis, and language inference. Its introduction has significantly improved the performance of various NLP applications, making it a cornerstone for many modern AI systems, including those like Jaxon that incorporate BERT into their processing pipelines.
- Category –
A collection of terms or entities that are linked either semantically (by meaning) or statistically (by data trends), without adhering to strict hierarchical structures such as genus/species, parent/child, or part/whole relationships. This grouping is based on common characteristics or themes that the items share, allowing for a broad classification that highlights similarities without imposing a rigid framework. Categories facilitate organization and analysis by clustering related items, making it easier to understand and navigate through large sets of data or concepts. Unlike hierarchical classifications, categories offer flexibility, accommodating items that share common attributes without necessitating a direct or exclusive relationship, thereby supporting a more inclusive and associative approach to classification.
- Chain of Thought –
The sequential flow of ideas or concepts expressed in a piece of text or conversation. It represents the logical progression of arguments, explanations, or narratives within a discourse, where each statement or utterance builds upon the preceding ones. Understanding the chain of thought is crucial for comprehending the underlying meaning and intent conveyed by the speaker or writer. In artificial intelligence and natural language processing, modeling and analyzing the chain of thought enable systems to generate coherent responses, engage in meaningful dialogue, and infer contextually relevant information from textual input.
- Chunk –
In the context of AI and Natural Language Processing (NLP), a chunk refers to a semantically meaningful segment of text, typically consisting of a group of words, phrases, or sentences. Chunks are created to simplify and optimize the processing and understanding of larger bodies of text by breaking them down into smaller, more manageable pieces that retain their contextual meaning.
- Chunking strategy –
In AI, chunking strategy refers to the process of dividing text into smaller, meaningful segments or “chunks.” This can be done using two main approaches: structural chunking, which breaks down text based on predefined structures such as paragraphs or sentences, and semantic chunking, which groups text by meaning and context. While semantic chunking allows for deeper understanding, structural chunking is more straightforward and commonly used due to its simplicity and efficiency in many AI applications. Both strategies help improve the processing, analysis, and comprehension of large text bodies in AI systems.
- Classification –
Classification in the context of document management involves the process of assigning documents to one or more predefined categories or classes. This systematic organization allows for easier sorting, management, and retrieval of documents based on their content, themes, or other distinguishing characteristics. Often facilitated by machine learning algorithms, classification automates the analysis and categorization of documents, enabling efficient handling of large datasets. The use of synthetic labels represents an advanced technique where artificial intelligence generates accurate labels for categorizing content, minimizing the need for extensive human-labeled data. This approach streamlines data organization, ensuring documents are easily sortable and accessible, thus enhancing data management efficiency.
- Clique –
In the mathematical area of graph theory, a clique is a subset of vertices of an undirected graph where every two distinct vertices are adjacent, meaning there is a direct edge connecting them. In other words, a clique is an induced subgraph that is complete.
In practical terms, cliques are used to identify tightly-knit communities within a network, as they represent groups of nodes with strong mutual connections. This concept is crucial in community detection, where nodes in a clique exhibit high levels of interaction or communication based on the edges connecting them.
Although cliques are similar to similarity searches in vector databases, which identify closely related data points, they focus on the structural connectivity within a graph rather than on vector similarity.
- Clustering –
The process of dividing a collection of documents into groups, known as clusters, based on their similarity. Each cluster gathers documents that are more alike to each other than to those in different clusters. This method is used to identify inherent structures or patterns within the data, without prior knowledge of the group assignments. Clustering is a form of unsupervised learning, meaning it discovers natural groupings within the data based on the features and content of the documents. It’s a powerful tool for data analysis, helping in the organization, summarization, and exploration of large datasets. Applications of clustering include topic discovery, pattern recognition, and information retrieval, making it a fundamental technique in data science and machine learning for enhancing the understanding and management of complex information.
- Cohesion –
Cohesion describes the logical and grammatical connections within a text, ensuring ideas flow seamlessly and parts are interlinked via linguistic devices like pronouns and conjunctions. The Cohesion Metric quantifies these aspects, assessing the relatedness of elements in texts or the unity within software classes, where a high score indicates a focused, single-function class or a text where ideas are closely interconnected. This metric is essential for evaluating textual clarity and the structural quality of software, aiming to enhance understandability and maintainability by ensuring components contribute meaningfully to the overall objective.
- Confabulation –
A phenomenon in artificial intelligence (AI) systems where the model generates erroneous or fabricated information without awareness of its inaccuracy. In the context of AI hallucinations, confabulation manifests as the generation of plausible but false content by the model, often due to limitations in training data or the underlying algorithms. These hallucinations can occur when the AI model attempts to fill in gaps in its understanding or generate responses beyond its training scope, leading to the production of deceptive or nonsensical outputs. Understanding and mitigating confabulation are essential in ensuring the reliability and trustworthiness of AI systems, particularly in critical applications such as healthcare, finance, and autonomous vehicles.
- Corpus –
A large and structured collection of texts, which are usually stored and processed electronically. This extensive compilation of written or spoken material serves as a foundational resource for linguistic research, natural language processing (NLP), and machine learning models. By analyzing a corpus, researchers and algorithms can uncover patterns, frequencies, and structures within a language, aiding in the development of technologies like speech recognition, text analysis, and automated translation. The structured nature of a corpus allows for systematic study across various texts, making it an invaluable tool for both theoretical and applied language studies.
- Cyber-Physical Systems (CPS) –
Encompasses the intricate integration of cyber and physical spaces, where hardware and software components are deeply interwoven, operating across various spatial and temporal scales. CPS exhibit diverse behavioral modalities and interact dynamically, adapting their interactions based on contextual changes. This convergence enables seamless communication and coordination between physical devices and computational systems, facilitating functionalities such as real-time monitoring, control, and automation across interconnected environments. By bridging the gap between the digital and physical realms, CPS revolutionize numerous domains, including smart infrastructure, healthcare, transportation, and manufacturing, ushering in a new era of interconnectedness and efficiency.
- Cyber-Physical-Social Systems (CPSS) –
Extend Cyber-Physical Systems (CPS) by incorporating human elements into the framework. These systems, prevalent in today’s AI-driven and ubiquitous computing landscape, integrate cyber, physical, and social components. CPSS are omnipresent in everyday life, manifesting in innovations like smart vehicles, Internet of Things (IoT), and augmented reality (AR). In industry, they drive advancements such as Industrial Internet of Things (IIoT) and Digital Twins, optimizing processes and enhancing productivity. Additionally, CPSS play crucial roles in defense applications, including augmented/virtual reality (AR/VR), avionics, and strategic operation methodologies like kill chains. This integration of human factors enriches system capabilities, fostering more adaptive, responsive, and context-aware functionalities across diverse domains.
- Data Labeling, Annotation, and Tagging –
The collective process of enhancing data with additional information to facilitate machine learning and automated analysis. Data labeling involves assigning labels, typically text or numerical values, to data, making it suitable for supervised learning where labeled data trains models to make predictions on new, unlabeled data. Annotation is a broader term encompassing any additional information added to data, including bounding boxes, image captions, or metadata, aiding in model training. Tagging is a specific form of annotation involving attaching descriptive keywords, or “tags,” to organize and classify data, commonly used in social media and content organization applications.
- Data Structure Theory –
Understanding the theory of a data structure involves grasping its attributes, data management mechanisms, performance implications, and suitable application contexts. This knowledge is essential for software developers and computer scientists when designing AI solutions or conducting data analytics. In algorithms dealing with graph data structures, predicate functions play a crucial role in evaluating whether a node or edge meets specific criteria. For example, in graph traversal algorithms like depth-first search or breadth-first search, predicate functions assist in determining the eligibility of nodes or edges for traversal based on predefined conditions or constraints.
- Deep Learning –
A specialized subset of machine learning that involves neural networks with three or more layers. These multi-layered neural networks are designed to learn from vast amounts of data, gradually improving their ability to recognize patterns, make predictions, and solve problems. While a single-layer neural network can make basic predictions, the addition of multiple hidden layers allows for more complex, nuanced learning and processing. This depth enables the network to refine its accuracy significantly, capturing and modeling the intricacies within the data. Deep Learning has revolutionized fields such as image recognition, natural language processing, and autonomous vehicle navigation by providing a framework for machines to learn and make decisions with a degree of sophistication and precision that approaches human-like understanding.
- Denotation –
The explicit, literal meaning of a word, distinguishing it from connotation, which encompasses the implied or associated meanings. While machines excel at understanding and processing the denotative aspects of language, capturing the precise dictionary definitions, they often struggle with connotation. Connotation involves cultural, emotional, or associative nuances that extend beyond a word’s direct meaning, requiring a level of interpretive understanding that machines find challenging. This distinction is crucial in language processing and interpretation, where a word’s denotation is straightforward but its connotation can vary significantly, affecting the overall interpretation of texts.
- Dict –
Python’s efficient key/value hash table structure is called a “dict”. The contents of a dict can be written as a series of key:value pairs within braces { }, e.g. dict = {key1:value1, key2:value2, … }. The “empty dict” is just an empty pair of curly braces {}.
- Distilling Large Language Models (LLMs) –
The practice of training a compact, more resource-efficient model to replicate the functionality of a larger, more intricate LLM. This process involves training the smaller model on identical tasks as the larger counterpart, leveraging the predictions of the larger model as “soft targets” or guidance during training. By mimicking the behavior of the larger model, the distilled model aims to capture its performance while requiring fewer computational resources and memory. Distillation enables the deployment of LLMs in resource-constrained environments without compromising performance, facilitating their widespread adoption across diverse applications and platforms.
- Distributed Representations –
Encodes words or phrases as vectors, using language’s distributional properties from large datasets. Central to advanced NLP, this method supports deep learning by encapsulating semantic and syntactic subtleties in vectors, enabling nuanced language understanding. Word embeddings exemplify this, mapping words into vector spaces where relationships are defined by vector proximity. Such representations are pivotal for processing and comprehending complex language patterns, enhancing the performance of NLP applications by providing depth and accuracy in machine interpretation of text.
- Distributional Similarity –
Quantifies word similarity based on their distribution patterns across text, rather than direct semantic connections. This concept, rooted in the principle that words appearing in similar contexts tend to have related meanings, leverages large text corpora to analyze word usage. By examining how frequently words co-occur with others, it provides a measure of their similarity, enabling the identification of words with parallel usage patterns. This approach is fundamental in computational linguistics and NLP for tasks like synonym detection and semantic analysis, offering insights into the relational dynamics of language without relying solely on predefined semantic relationships.
- DSAIL Alignment –
If the DSL is coupled with the ontology for a given domain, we say the two artifacts are said to be “aligned”. Tightly coupled alignment implies that there is a mapping from one to the other. To promote greater flexibility and interoperability, we emphasize loosely coupled alignments.
In the context of a system that uses a domain-specific language (DSL) and an ontology to query and process a knowledge graph, the decision as to whether to couple, loosely or tightly, the DSL and the ontology of DSAIL depends on the specific application requirements. Coupling the DSL and the Ontology can provide benefits such as:
- Consistency: If the DSL and the ontology are tightly coupled, changes in the ontology can be directly reflected in the DSL. This can help maintain consistency between the two.
- Efficiency: Tight coupling can potentially lead to more efficient queries, as the DSL can be optimized based on the structure and semantics of the ontology.
On the other hand, loosely coupling the DSL and the Ontology can offer advantages like:
- Flexibility: Loose coupling can make it easier to modify or extend the DSL or the ontology independently.
- Interoperability: If the DSL is not tightly bound to a specific ontology, it may be easier to use the same DSL with different ontologies.
- Embedding Techniques –
A range of language modeling and feature learning methods in Natural Language Processing (NLP), where words or phrases are mapped to vectors of real numbers. These techniques allow semantically similar words to achieve comparable vector representations, facilitating tasks like semantic analysis and context recognition. Core to these techniques are embedding algorithms which learn these vector representations from large text corpora. By analyzing the distribution and usage patterns of words within a vast array of texts, these algorithms encode linguistic items into dense vectors, capturing nuanced semantic relationships and enabling sophisticated language understanding and processing capabilities.
- Ensemble –
The combination of several parallel machine learning models, all working on the same task, the results of which are combined in a (sometimes weighted) voting system to obtain a single prediction for the group of models. Using ensembles of weak labelers can sometimes allow the final labels to be much stronger than any of the labelers individually.
- Epistemological –
Pertains to the branch of philosophy concerned with the nature, scope, and limits of knowledge. It explores questions such as: How do we know what we know? What is the nature of knowledge? What are the criteria for something to be considered knowledge? Epistemology examines the justification of beliefs, the sources of knowledge, and the rationality of belief formation. It’s a fundamental concept in philosophy, particularly in fields like epistemology of science, epistemology of religion, and epistemology of mathematics.
- F1 Score –
The F1 score is a metric used to evaluate the performance of a classification model. It balances two key aspects:
- Precision: the proportion of true positive predictions out of all positive predictions made.
- Recall: the proportion of true positive predictions out of all actual positive cases.
The F1 score is the harmonic mean of precision and recall:
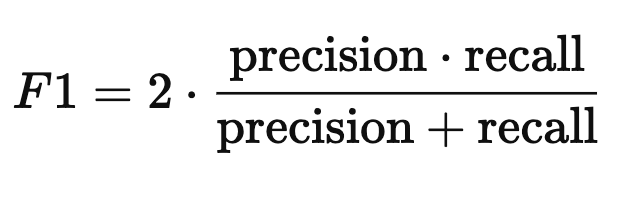
It’s especially useful when you need a balance between precision and recall, and when classes are imbalanced.
- Features –
Measurable properties or characteristics observed in data, essential for algorithms in pattern recognition, classification, and regression. The selection of informative, discriminating, and independent features is critical to algorithm effectiveness. Typically numeric, features also include structural types like strings and graphs, especially in syntactic pattern recognition. They serve as the foundation for models to learn, identify patterns, and make predictions by analyzing the inherent traits within the data.
- First-order logic (FOL) –
Also known as predicate logic, is a powerful formalism used for knowledge representation in artificial intelligence and computer science. It extends propositional logic by allowing the use of quantifiers and predicates, enabling the representation of complex statements about objects and their relationships.
Key Components of First-Order Logic
Constants:
Definition: Constants are symbols that represent specific objects in the domain.
Examples: If a, b, and c are constants, they might represent specific individuals like Alice, Bob, and Charlie.Variables:
Definition: Variables are symbols that can represent any object in the domain.
Examples: Variables such as x, y, and z can represent any object in the domain.Predicates:
Definition: Predicates represent properties of objects or relationships between objects.
Examples: P(x) could mean “x is a person”, while Q(x, y) could mean “x is friends with y”.Functions:
Definition: Functions map objects to other objects.
Examples: f(x) could represent a function that maps an object x to another object, like “the father of x”.Quantifiers:
- Universal Quantifier (∀): Indicates that a statement applies to all objects in the domain. For example, ∀x P(x) means “P(x) is true for all x”.
- Existential Quantifier (∃): Indicates that there exists at least one object in the domain for which the statement is true. For example, ∃x P(x) means “There exists an x such that P(x) is true”.
- Logical Connectives:
Definition: These include ∧ (and), ∨ (or), ¬ (not), → (implies), and
 (if and only if).
(if and only if).
Examples: P(x) ∧ Q(x, y) means “P(x) and Q(x, y) are both true”.- Equality:
Definition: States that two objects are the same.
Examples: x = y asserts that x and y refer to the same object. - Formal Concept Analysis –
A mathematical framework used for analysing relationships between objects and their attributes within a dataset. It identifies and organizes these relationships into a structure called a concept lattice, where each node represents a formal concept—a group of objects sharing a common set of attributes. This approach enables deeper insights into data organization, hierarchical patterns, and knowledge discovery.
In the context of AI, FCA is particularly useful for ontology development, semantic reasoning, and enhancing machine learning models by structuring and visualizing domain-specific knowledge. At Jaxon, we leverage FCA to refine AI systems’ understanding of complex domains, ensuring precise and reliable outputs.
- Formal Logic –
Also known as symbolic or mathematical logic, formal logic is the study of deductively valid inferences or logical truths. It abstracts the content of propositions, statements, or assertively used sentences and deductive arguments to focus on their structures or logical forms.
Symbolic artificial intelligence represents intelligence using abstract symbolic representations and precise logical rules, which are the core elements of formal logic.
As such, formal logic is a subset of symbolic AI like LLMs are a subset of machine learning.
- Foundation Models –
Large-scale pre-trained models serving as base structures for constructing fine-tuned models across various applications in artificial intelligence (AI). Developed through deep learning techniques like neural networks, they undergo training on extensive datasets. Notable examples include OpenAI’s GPT-3 series, renowned for their versatility in tasks like language understanding, translation, summarization, and code generation post fine-tuning. Key attributes include scale, transfer learning capabilities, multi-domain learning, and proficiency in few-shot or zero-shot learning scenarios. While impressive, these models pose challenges such as biases, potential misuse, and environmental impact due to resource-intensive training, necessitating ongoing efforts for responsible development and accessibility enhancement.
- Gradient-Blending –
A technique used in machine learning and optimization that involves combining gradients from different models or algorithms to improve the performance of a learning algorithm. This method leverages the strengths of multiple gradient sources to adjust model parameters more effectively, facilitating a more robust convergence to optimal solutions. Gradient blending is particularly useful in scenarios where single models might struggle due to their complexity or the diversity of the data. By blending gradients, it’s possible to achieve a more nuanced update of model weights, enhancing the model’s ability to learn from the data and ultimately improving prediction accuracy and generalization.
- Grokking –
A phenomenon in machine learning where a model generalizes well on unseen data after overfitting its training data.
- Ground Atom –
In the context of logic, a ground atom is an atomic formula where all of its argument terms are ground terms. Let’s break it down:
- An atomic formula (also known as an atom) is a formula with no deeper propositional structure, meaning it contains no logical connectives or equivalently, it has no strict sub-formulas.
- A ground term is a term that does not contain any variables.
So, if P is an n-ary predicate symbol and t1, t2, …, tn are ground terms, then P(t1, t2, …, tn) is a ground atom.
For example, consider a clause (disjunction of literals) obtained from a first-order logic formula. Then an atomic statement obtained by replacing all variables by values is called a ground atom.
- Hierarchical Relationship –
The structured connection between terms, delineating broader (generic) to narrower (specific) or whole-part relationships. This organizational method categorizes concepts in a way that reflects their levels of specificity or their compositional relationships. Hierarchies enable users to navigate from general categories to more detailed instances, facilitating efficient information retrieval and understanding of the context and relationships among terms. Such structuring is fundamental in various domains, including taxonomy, information science, and data management, aiding in the systematic organization and classification of knowledge.
- Hypernym –
A term whose meaning encompasses the meanings of more specific words, serving as a broader category under which these specific terms fall. For example, “color” is a hypernym of “red,” as it includes “red” within its broader classification along with other colors. Hypernyms are essential in linguistics and semantic analysis for organizing vocabulary hierarchically, facilitating an understanding of the relationship between general and specific terms. This concept aids in natural language processing and information retrieval by allowing algorithms to recognize the levels of specificity in language and improve the accuracy of semantic interpretation.
- K-means –
A method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. K-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells.
- Knowledge Graph (KG) –
A structured representation of knowledge, typically in the form of a graph, where entities are nodes and relationships between entities are edges. Knowledge graphs organize information in a way that captures the semantic relationships and contextual associations between entities, enabling efficient storage, retrieval, and inference of knowledge. KGs are widely used in various domains, including search engines, recommendation systems, question answering, and semantic web applications. They facilitate the integration of heterogeneous data sources and support complex queries and reasoning tasks, making them valuable tools for representing and leveraging structured knowledge in diverse applications.
- Large Language Model (LLM) –
A sophisticated artificial intelligence model designed to understand and generate human-like text at scale. LLMs leverage deep learning techniques, particularly neural networks with numerous parameters, to learn patterns and structures in vast amounts of text data. These models excel in natural language processing tasks such as text generation, translation, summarization, and question answering. LLMs have revolutionized various applications, from chatbots and virtual assistants to content generation and language understanding, by enabling machines to comprehend and generate human language with remarkable fluency and context sensitivity.
- Latent Dirichlet Allocation (LDA) –
A generative statistical model used to discover abstract topics within a collection of documents. It assumes that each document is a mixture of a small number of topics and that each word in the document is attributable to one of the document’s topics. LDA helps in identifying unobserved (latent) topic structures within sets of observations, making it possible to explain similarities in the data based on these hidden groups. By analyzing the distribution of words across documents, LDA can infer the topic distribution that generated the observed words in each document, facilitating the understanding of large text corpora by grouping similar documents and words under common topics. This model is widely applied in natural language processing and information retrieval to enhance the organization, summarization, and exploration of large datasets.
- Latent Semantic Indexing (LSI) –
Also known as Latent Semantic Analysis (LSA), a technique in text indexing and retrieval that employs Singular Value Decomposition (SVD), a mathematical method, to uncover patterns in the relationships between terms and concepts within an unstructured text corpus. LSI operates on the assumption that words appearing in similar contexts likely share meanings. This method excels in extracting the conceptual content from texts by identifying associations among terms found in analogous contexts. LSI’s strength lies in its ability to discern the underlying semantic structure of a text collection, enhancing the precision of information retrieval and document classification by going beyond mere keyword matching to understand the essence of the text.
- Lemmatizing –
Akin to stemming in natural language processing, lemmatizing reduces words to their base form. Unlike stemming, which may produce non-existent words, lemmatization ensures outcomes are actual dictionary words. It involves contextual and morphological analysis to accurately strip inflections, returning the root word, or lemma. This distinction is crucial for semantic processing, as lemmatization preserves the word’s original meaning, making it more suitable for tasks requiring precise language understanding.
- Logical Rules –
The key syntactic construct that enables changes to atoms formed with non-static predicates.
A logic program is a set of rules and facts. Rules are logical formulas of the form “If P then Q”, and facts are rules with no conditions.
To entail means to logically infer. That is, if a set of statements entails a conclusion, then that conclusion is a logical consequence of those statements.
In the context of logic programming, to “produce all atoms entailed by a logic program” means to compute all the atomic formulas (or atoms) that can be logically inferred from a given set of logical rules and facts.
An atom is a basic formula with no logical connectives.
- Memory –
A repository within the agent’s architecture, enabling the retention and recall of past interactions for enhanced decision-making and problem-solving. These interactions encompass engagements with external entities (such as humans or other agents) or tools utilized within the system. Memory functions can be categorized into short-term and long-term storage mechanisms. Short-term memory preserves recent interactions, often in a limited capacity, such as a history of the most recent tool usages. Long-term memory stores past interactions deemed relevant to the current context, facilitating informed decision-making based on historical patterns and similarities.
- Meronym –
Signifies a component or part of a larger entity, yet is employed to represent the whole. For instance, using “faces” to refer to “people,” as in “I see several familiar faces present,” illustrates this concept. Meronyms highlight the linguistic practice of mentioning a part while implying the entire object or group, a common technique in everyday language that enriches descriptive detail and specificity. This concept is essential in semantic analysis and natural language processing, facilitating a deeper understanding of language’s nuanced ways of expressing relationships between parts and wholes.
- Model Drift –
The phenomenon where the statistical properties or distribution of data change over time. This shift in data distribution can result in reduced accuracy, degraded performance of machine learning models, and unexpected outcomes. Model drift poses significant challenges in maintaining the effectiveness and reliability of machine learning systems, as models trained on historical data may become less suitable for making accurate predictions in evolving environments. Monitoring and addressing model drift are essential for ensuring the continued effectiveness and relevance of machine learning models in real-world applications.
- Multi-modal Network –
Integrates multiple data sources such as images, text, audio, and video within AI systems. Designed to process and analyze diverse forms of information simultaneously, these networks excel in understanding complex, real-world scenarios by combining insights from various sensory inputs. This approach allows for a more comprehensive analysis and interpretation of data, enhancing the system’s ability to perform tasks like image recognition, natural language understanding, and multimedia content analysis. Multimodal networks represent a significant advancement in AI, reflecting an effort to mimic human cognitive abilities by interpreting a wide range of information types.
- N-grams –
Consecutive sequences of n words in a text, ranging from single words to strings of two or more uninterrupted word forms. Utilized in computational linguistics and natural language processing, n-grams serve as fundamental components for modeling language data, facilitating tasks such as text prediction, spelling correction, and language identification. By analyzing the frequency and patterns of these word sequences, algorithms can better understand and generate human-like text, capturing the nuances of language structure and usage.
- Named Entity –
Refers to real-world objects identifiable within text, including persons, locations, organizations, and products, among others. Central to information extraction, named entity recognition (NER) is a process where AI algorithms identify and categorize these entities based on context. This technique enhances data’s semantic understanding, aiding in tasks such as content categorization, relationship extraction, and data organization. By pinpointing specific entities, NER provides a structured interpretation of unstructured data, crucial for various applications like search engines, content recommendation systems, and customer service automation.
- Named-Entity Recognition (NER) –
Targets the identification and categorization of named entities within text into predefined groups such as locations, persons, or organizations. This extraction method excels in straightforward tasks, like pinpointing references to “New York City.” However, its ability to recognize and associate various nicknames or colloquial terms, like “the Big Apple,” with the same entity can be limited. NER’s effectiveness lies in its precision for direct mentions, though it may require additional contextual or semantic analysis tools to fully capture the breadth of language used to refer to specific entities.
- Natural Language Processing (NLP) –
A branch of artificial intelligence (AI) centered on the interaction between computers and human language, encompassing verbal communication languages such as English, Arabic, or Russian. NLP technologies enable machines to understand, interpret, and generate human language, facilitating tasks like translation, sentiment analysis, and content summarization. By analyzing text and speech, NLP algorithms enhance human-computer interactions, enabling more intuitive communication. This capability significantly improves the accessibility and efficiency of technology in meeting human needs, fostering seamless interactions between humans and machines across various domains.
- Neural Network –
A computing system inspired by the biological neural networks found in animal brains. This framework supports various machine learning algorithms in processing complex data inputs. Unlike a singular algorithm, a neural network comprises multiple layers of interconnected nodes or “neurons” that simulate the way biological neurons signal to one another. These networks are capable of learning from data through adaptation, making them powerful tools for tasks ranging from image recognition to language processing. By adjusting connections based on input data, neural networks can identify patterns, make predictions, and solve problems in ways that mimic human cognition.
- Online Learning –
A machine learning approach where data is processed sequentially, allowing models to update predictions for future data at each step. Unlike batch learning, which learns from the entire dataset in one go, online learning adapts to new data as it arrives, making it ideal for applications where data is continuously generated or updated. This method ensures models remain current with the latest information, enhancing their accuracy and relevance over time. Online learning is especially useful in dynamic environments, such as stock market prediction or real-time user recommendation systems, where immediate responsiveness to new data is crucial.
- Ontology –
An ontology is a structured framework for organizing information, combining a detailed description of concepts and their relationships with inference rules to facilitate logical reasoning and knowledge discovery. It uses instances of concepts, attributes of instances and classes, restrictions of classes, and rules (if-then statements) to describe the logical inferences that can be drawn from assertions and axioms. This framework allows for the inference of new knowledge from existing data and ensures data model consistency.
Ontologies are crucial in various applications, from the semantic web to knowledge management. They enable both humans and machines to interpret complex data by defining terms and their interrelations within a specific domain. For example, upper-level ontologies like DOLCE describe general concepts and relations, while domain-specific ontologies like the Gene Ontology focus on particular fields.
The Web Ontology Language (OWL) is often used to describe resources in ontologies, leveraging description logic axioms and serialized using the Resource Description Framework (RDF). This ensures logical consistency and enables advanced search capabilities, enhancing data interoperability and supporting decision-making processes in artificial intelligence systems.
In practice, ontologies are employed for various purposes, such as ensuring logical consistency in graph databases or facilitating knowledge organization and retrieval. For instance, if an ontology states that “Human” and “Sponge” are disjoint classes, it would fail a consistency test if an instance like John (a human) were categorized under both classes. By providing a clear framework for information structuring, ontologies play a pivotal role in enabling semantic web services and improving knowledge management.
- Open-World Reasoning –
A concept in logic and artificial intelligence that operates under the open-world assumption (OWA). The OWA is the assumption that the truth value of a statement may be true irrespective of whether or not it is known to be true. It is the opposite of the closed-world assumption, which holds that any statement that is true is also known to be true.
In a formal system of logic used for knowledge representation, the OWA codifies the informal notion that in general no single agent or observer has complete knowledge, and therefore cannot make the closed-world assumption. The OWA limits the kinds of inference and deductions an agent can make to those that follow from statements that are known to the agent to be true. In contrast, the closed-world assumption allows an agent to use the lack of knowledge that a statement is true, to infer that the statement is false.
For example, consider the statement: “Juan is a citizen of the USA.” Now, what if we were to ask “Is Juan a citizen of Colombia?” Under a closed-world assumption, the answer is no. Under the open-world assumption, it is “I don’t know”.
An open-world reasoner is a problem-solving system which can use opportunistic, cross-domain reasoning. An open-world reasoner can solve problems that would fail with a closed-world reasoner precisely because the former can use seemingly irrelevant information from other domains.
Semantic Web languages such as OWL make the open-world assumption. The absence of a particular statement within the web means, in principle, that the statement has not been made explicitly yet, irrespective of whether it would be true or not, and irrespective of whether we believe that it would be true or not. In essence, from the absence of a statement alone, a deductive reasoner cannot (and must not) infer that the statement is false.
- Parameter –
Refers to a characteristic vital for defining, classifying, or assessing a system’s performance, status, or condition. In the context of computational models and algorithms, parameters are elements that influence the system’s operation or outcome, such as settings that control the model’s behavior or variables that define its state. The selection of optimal parameters is critical for maximizing a model’s effectiveness and accuracy, often involving automated processes to evaluate and choose the best settings based on the data at hand. This process is essential in tailoring models to specific datasets, ensuring they perform optimally in various tasks.
- Parameter Efficient Fine Tuning (PEFT) –
A category encompassing techniques aimed at efficiently training large models, rather than denoting a specific technique itself. PEFT techniques optimize the fine-tuning process to achieve better efficiency while retaining model performance. Examples of techniques falling under the PEFT umbrella include LoRA and Adapters. These approaches streamline the training of large models by focusing on parameter efficiency, enabling faster convergence and improved resource utilization during fine-tuning tasks. By adopting PEFT strategies, practitioners can enhance the scalability and effectiveness of model training processes in resource-constrained environments.
- Parameterization –
The process of determining the optimal configuration values, known as “hyperparameters,” for a machine learning algorithm to achieve maximum effectiveness on a specific dataset and prediction task. This involves adjusting key settings that govern the algorithm’s learning process, such as learning rate, regularization strength, and network architecture, among others. Parameterization is crucial for fine-tuning models to ensure they accurately capture the underlying patterns in the data, thereby enhancing their predictive performance. This tailored approach allows algorithms to adapt to the nuances of different data types and objectives, optimizing their functionality for diverse applications.
- Perplexity –
A metric used to evaluate the effectiveness of a language model in predicting a given sample. It quantifies the uncertainty associated with the model’s predictions for the next word in a sequence. A higher perplexity value indicates poorer predictive performance. The perplexity formula is represented as:
PP(W) = P(w1, w2, …, wN)-1/N
Here, PP denotes perplexity, W is the test set, P signifies the probability of the test set, and N represents the number of words in the test set.
- Pipeline –
Describes the structured sequence of stages in the machine learning (ML) process, facilitating the flow of data from its raw state to a form that yields useful information. This setup ensures that each component of the ML process, from data preprocessing and feature extraction to model training and evaluation, is interconnected, with the output of one stage serving as the input for the next. Pipelines streamline the transformation of data, automate repetitive tasks, and enhance the reproducibility of ML workflows, thereby optimizing the efficiency and effectiveness of developing and deploying ML models. This concept is fundamental in managing complex data processing tasks, ensuring a smooth transition of data through various processing steps.
- Precision & Recall –
Key metrics in pattern recognition and classification, measuring the accuracy and comprehensiveness of a model’s performance. Precision quantifies the proportion of relevant instances among the retrieved instances, highlighting the model’s accuracy in selecting relevant items. Recall, on the other hand, assesses the ratio of correctly identified relevant instances to the total number of actual relevant instances, indicating the model’s ability to capture all pertinent items. Both metrics rely on an understanding of relevance, serving as crucial indicators for evaluating the effectiveness of a model in identifying and retrieving relevant information. Optimizing both precision and recall is essential for achieving a balance between accuracy and completeness in search and classification tasks.
- Predicate Function –
Assesses the properties of a specified data structure and yields a Boolean value (true or false) based on the theoretical principles governing that data structure. While the use of predicate functions in programming doesn’t inherently involve artificial intelligence (AI), they serve as vital components in AI systems. These functions are foundational across various programming paradigms, notably functional programming, and are instrumental for decision-making, data filtering, and other logical operations. In AI systems, predicate functions contribute to tasks such as pattern recognition, rule-based reasoning, and filtering relevant information, enabling efficient data processing and decision-making.
- Prompt Engineering –
A process in natural language processing (NLP) where prompts, or input queries or instructions, are carefully crafted to elicit desired responses from language models. Prompt engineering involves designing prompts that guide the model towards generating accurate, relevant, and contextually appropriate outputs for specific tasks or applications. This iterative process may involve adjusting the wording, structure, or formatting of prompts to optimize model performance and mitigate biases or errors. By tailoring prompts to the intended use case and dataset, prompt engineering enhances the effectiveness and reliability of language models in various NLP tasks, including question answering, summarization, and dialogue generation.
- Reasoning Systems –
Reasoning systems are computational frameworks designed to simulate human reasoning or automate the decision-making process in artificial intelligence (AI) applications. These systems utilize a structured approach to process information, deduce new knowledge, solve problems, or reach decisions based on logical operations. Three fundamental concepts within reasoning systems that ensure their integrity, correctness, and alignment with human-like reasoning are constraints, assertions, and assumptions:
- Constraints: A condition that must be maintained across all parts of the system or program at all times. This defines the boundaries of the system and ensures it operates within predefined limits and adheres to specific requirements or conditions.
- Assertions: A statement expected to be true at one particular point in a program’s flow, or in one specific context. Essentially, a localized constraint. Assertions are implemented checks that verify the system’s state aligns with the expected conditions at critical moments, thus confirming that the broader constraints are being adhered to.
- Assumptions: Core beliefs about language patterns and context that are crucial for the model’s design and functionality. Assumptions form the basis upon which reasoning systems interpret information and make decisions. They are embedded within the system to guide its understanding of the world, fill in the gaps where explicit information is lacking, and help in making inferences. Like constraints and assertions, assumptions are vital for ensuring that the system’s operations are grounded in a logical and consistent representation of its operating environment.
One might use a set of assertions to test that constraints are being met, while assumptions underpin the system’s ability to process and interpret information in a human-like manner. Constraints are conceptual limitations of the system, and assertions are specific implemented tests that prove those constraints. Together, these elements ensure the system’s reliability, accuracy, and alignment with human reasoning processes.
- Regime Change –
Denotes a significant alteration in the characteristics or behavior of a data stream, leading to challenges for models previously trained on that data. An example is a trading algorithm optimized for bull markets struggling in bear market conditions due to the fundamental differences in market dynamics. Recognizing a regime change is critical for maintaining model performance, as it necessitates updating the model with new, relevant training data to adapt to the changed environment. This adjustment ensures the model remains effective and accurate in predicting outcomes under the new regime, highlighting the importance of flexibility and adaptability in model design and training.
- Reinforcement Learning –
An ML paradigm where an agent learns optimal behavior through trial-and-error interactions with an environment. By performing actions and receiving feedback in the form of rewards or penalties, the agent identifies strategies that maximize cumulative rewards over time. This learning process enables the agent to make informed decisions and adapt its actions to achieve specific goals. Reinforcement learning is pivotal in areas requiring decision-making under uncertainty, such as robotics, game playing, and autonomous vehicles, empowering agents to autonomously improve their performance based on direct experiences.
- Retrieval Augmented Generation (RAG) –
A technique in natural language processing (NLP) that combines elements of information retrieval and text generation to produce high-quality responses to queries or prompts. RAG models incorporate a retrieval mechanism to access relevant information from a large knowledge source, such as a database or corpus, and then generate responses based on this retrieved information. This approach enhances the relevance and coherence of generated text by leveraging the wealth of knowledge available in the retrieval step. RAG has demonstrated effectiveness in various NLP tasks, including question answering, summarization, and dialogue generation, contributing to more accurate and contextually appropriate outputs.
- Multi-Hop RAG (MHQA): A specialized variant of RAG tailored for tasks requiring the chaining together of multiple facts from the database to answer a question. In Multi-Hop RAG, the model iteratively retrieves and integrates information from the knowledge source, traversing multiple hops or steps to derive a comprehensive response. This capability enables the handling of complex queries that demand deeper reasoning and integration of disparate pieces of information, enhancing the model’s ability to address nuanced questions and provide more comprehensive answers.
- Semantic Entropy –
A measure of uncertainty or unpredictability in the meaning of a piece of information. Unlike traditional entropy, which quantifies uncertainty in a set of data, semantic entropy focuses on the variability and ambiguity in interpreting the meaning and context behind the data. High semantic entropy indicates greater complexity and difficulty in pinpointing a definitive interpretation, which can lead to issues such as hallucinations in AI outputs. Reducing semantic entropy involves enhancing the contextual understanding and accuracy of AI models, leading to more reliable and coherent information processing.
- Semi-Supervised Learning –
A machine learning approach that utilizes both labeled and unlabeled data for training, combining a small subset of annotated examples with a larger volume of unannotated ones. This methodology bridges the gap between supervised learning, which relies entirely on labeled data, and unsupervised learning, which uses unlabeled data. By leveraging the structure and distribution of the unlabeled data, semi-supervised learning can improve learning accuracy with less manually labeled data, making it particularly useful in scenarios where obtaining comprehensive labeled datasets is costly or impractical. This approach is effective for tasks like classification, regression, and clustering, enhancing model performance with limited supervision.
- Signature in First-Order Logic –
In first-order logic, a signature is a set of symbols of two kinds of constants:
- Function constants
- Predicate constants
Each of these has a nonnegative integer, called the arity, assigned to each symbol.
Moreover,
- Function constants of arity 0 are called object constants
- Predicate constants of arity 0 are called propositional constants.
- Supervised Learning –
A machine learning technique where the goal is to learn a mapping from inputs to outputs based on example input-output pairs. This process involves analyzing labeled training data—each example consisting of an input paired with the correct output—to infer a function that can predict outputs for new, unseen inputs. The effectiveness of supervised learning hinges on the algorithm’s ability to generalize from the training data to novel situations effectively. This generalization is crucial for the algorithm to accurately assign class labels to unseen instances, making supervised learning a foundational approach for tasks such as classification and regression, where predicting precise outcomes based on historical data is essential.
- Symbolic-Enhanced Neural Networks –
Also known as neuro-symbolic AI, combines the strengths of neural networks and symbolic reasoning to create more robust and interpretable AI systems.
- Systems of Logic –
Propositional logic and predicate logic are two different systems of logic that are used to represent and analyze the structure of arguments. Here’s a brief overview of the differences:
Propositional Logic:
Deals with propositions, which are statements that can be either true or false.
Analyzes the logical operators and the structure of compound statements built from these propositions.
Does not consider the internal structure of propositions; it treats them as atomic units.
Uses logical connectives like AND ( ∧ ), OR ( ∨ ), NOT ( ¬ ), IF…THEN ( → ), and IF AND ONLY IF ( ).
).Predicate Logic:
Extends propositional logic by dealing with predicates, which are functions that can be applied to objects in a domain of discourse.
Considers the internal structure of propositions, allowing for a more detailed analysis of arguments.
Includes quantifiers like the universal quantifier ( ∀ ) and the existential quantifier ( ∃ ), which allow for statements about ‘all’ or ‘some’ objects within a domain.
Allows for a more expressive language to discuss properties of objects and relationships between them.In essence, propositional logic is concerned with the truth values of statements without regard to their content, while predicate logic can express and reason about the properties of objects and the relationships between them. Predicate logic is more powerful and expressive, capable of representing more complex statements about the world.
- Taxonomy –
A structured arrangement comprising items and their attributes organized in a hierarchical manner. This organizational framework categorizes entities based on shared characteristics, allowing for systematic classification and organization. Taxonomies are commonly used in various fields, including biology, information science, and knowledge management, to facilitate efficient data retrieval, analysis, and understanding. By delineating relationships and dependencies between different items, taxonomies enable researchers, practitioners, and systems to navigate and comprehend complex datasets effectively. This hierarchical structure enhances the accessibility and usability of information, fostering clearer insights and facilitating decision-making processes across diverse domains.
- Temperature –
Turning up or down refers to adjusting the model’s “temperature” parameter to a higher or lower setting. The temperature parameter is crucial in controlling the randomness or creativity in the model’s responses.
TEMPERATURE SETTING DESCRIPTION EFFECT ON OUTPUTS USE CASES High Temperature (Closer to 1 or above) Results in more random, diverse, and creative outputs. The model takes risks in language generation, producing varied and sometimes unexpected or less probable responses. May generate creative or unusual sentences, but can also lead to less coherent or relevant responses. Creative tasks like poetry or story writing might benefit from higher temperature settings to introduce more creativity and novelty. Low Temperature (Closer to 0) Makes the model’s responses more deterministic and conservative. The model is likely to choose the most probable next word or phrase, leading to more predictable and consistent outputs. Generally produces more reliable, coherent, and contextually appropriate responses, but with less variation and creativity. Tasks requiring accuracy and coherence, like factual summarization or technical explanations, are better suited to lower temperature settings. Adjusting the “temperature” parameter in an LLM refers to controlling the randomness or creativity in the model’s responses. Lowering the temperature reduces randomness, leading to more predictable and coherent outputs, while increasing it introduces more creativity and diversity.
- Tensors –
Mathematical entities utilized to represent physical properties, extending beyond scalars and vectors. Tensors serve as a generalization, where scalars correspond to zero-rank tensors, and vectors to first-rank tensors. Unlike vectors, tensors permit different data types across dimensions, resembling dataframes. In modern contexts, especially with embedding considerations, all data can be conceptualized as tensors, providing a unified framework. Furthermore, in a broader perspective, everything else, including relationships and structures, can be depicted as graphs, emphasizing the interconnected nature of data and concepts across various domains.
- Term Frequency – Inverse Document Frequency (TFIDF) –
A technique used to represent text data by considering the frequency of words in a document relative to their occurrence across multiple documents. In TFIDF, each word’s importance is determined by two factors: its frequency in the current document (Term Frequency) and its rarity across all documents (Inverse Document Frequency). This normalization process ensures that common words are downweighted while rare, contextually significant words are upweighted, resulting in a more informative representation of the text data. TFIDF is widely used in information retrieval, text mining, and natural language processing tasks to improve the relevance and discriminative power of features extracted from text.
- Thunk –
A subroutine in computer programming used to delay a calculation until its result is needed or to insert operations at the beginning or end of another subroutine. Thunks are often used in compiler code generation. They can also be used to simulate lazy evaluation and delay the computation of function arguments in functional programming.
- Tokenization –
The process of dividing text into smaller units, such as words or sentences, to facilitate analysis and processing. In tokenization, text is segmented into individual tokens, which can be words, phrases, or punctuation marks, depending on the specific task or requirements. This technique is fundamental in natural language processing (NLP) tasks, enabling algorithms to parse and understand textual data more effectively. By breaking down text into manageable units, tokenization forms the basis for various NLP tasks, including part-of-speech tagging, named entity recognition, and syntactic analysis, allowing algorithms to extract meaningful information and derive insights from text data.
- Tokens –
Fundamental elements of text or code utilized by LLM AI systems for language processing and generation. These units can encompass characters, words, subwords, or other text segments, depending on the adopted tokenization method or scheme. Tokenization partitions the input text or code into discrete tokens, enabling the AI model to comprehend and manipulate language effectively. By representing linguistic components as tokens, LLMs streamline the processing and generation tasks, facilitating tasks such as text understanding, translation, summarization, and code generation with greater precision and efficiency.
- Topic Model –
Statistical algorithms, also known as probabilistic topic models, designed to unveil the latent semantic structures within extensive text bodies. These models assist in organizing and providing insights into large collections of unstructured text, aiding comprehension in the era of information overload. Originally developed for text mining, topic models have expanded their utility to detect instructive structures in various data types, including genetic information, images, and networks, with applications in fields like bioinformatics. Jaxon utilizes topic models to generate labels, leveraging their ability to discern meaningful themes and patterns within data.
- Unary Predicate –
In the context of logic and reasoning, a unary predicate is a predicate that takes a single argument. For example, in the statement “John is a student”, “is a student” is a unary predicate that takes “John” as its argument.
When we say “treating unary predicates as ground atoms”, it means that we are considering each instance of a unary predicate as a separate, distinct fact or piece of knowledge. This is often done in the context of reasoning over graphical structures, such as knowledge graphs.
For example, consider a knowledge graph where nodes represent individuals and unary predicates represent properties of those individuals. If we have a unary predicate Student(John), treating this unary predicate as a ground atom means considering Student(John) as a distinct piece of knowledge. This allows us to reason about John being a student independently of other facts in the knowledge graph.
- Unsupervised Learning –
A machine learning branch that learns from unlabeled test data, lacking explicit categorization or classification. Unlike supervised learning, unsupervised learning does not rely on labeled feedback. Instead, it identifies patterns and commonalities within the data, enabling it to react based on the presence or absence of such patterns in new data. This approach is valuable for tasks where labeled data is scarce or unavailable. For instance, Jaxon utilizes unsupervised learning to create topic labels, leveraging its ability to discern underlying structures and themes within unstructured data without explicit guidance.
- Validation and Verification in Modeling –
In modeling, validation and verification are distinct processes serving different purposes. Validation entails assessing the extent to which a conceptual model accurately represents the intended use cases envisioned by the developer. It examines how well the model captures reality and incorporates essential features, ensuring alignment with the developer’s objectives. Conversely, verification involves confirming that a model implementation faithfully realizes the intended use cases when executed with real data, software, and hardware. In essence, verification verifies whether the code adheres to specifications, while validation evaluates whether the specifications meet customer requirements. In the DSAIL metamodeling process, initial stages focus on design verification, while later stages emphasize code generation and testing for verification purposes.
- Variance –
Refers to the disparity in predictions generated by a machine learning model when trained on diverse datasets, highlighting its sensitivity to fluctuations in data. Variance quantifies the extent to which model outputs deviate across different training instances, reflecting its susceptibility to changes in input variables or dataset compositions. High variance implies that the model is overly influenced by fluctuations in training data, potentially leading to overfitting and reduced generalization performance. Managing variance is crucial in ensuring model robustness and reliability across various datasets, enhancing its ability to generalize well to unseen data and improve overall predictive accuracy.
- Vector Database (Vector DB) –
A storage system designed to efficiently store and retrieve vector representations of data objects. Vector databases are optimized for handling high-dimensional vectors, which are commonly used in machine learning and natural language processing tasks such as similarity search, recommendation systems, and semantic indexing. These databases typically provide fast query performance and support operations such as nearest neighbor search, vector indexing, and similarity computation. Vector databases play a crucial role in enabling scalable and efficient processing of large-scale vector data in applications where similarity or distance metrics are essential for data retrieval and analysis.
- Vectorization –
The transformation process of converting non-numeric data and features into numerical representations suitable for consumption by machine learning algorithms. This conversion is essential as most machine learning algorithms expect numerical vector representations to operate effectively. An example of vectorization is converting text data, such as sentences, into a bag-of-words vector, where each word is represented by a numeric value indicating its frequency or presence in the text. Vectorization enables algorithms to process and analyze diverse types of data, facilitating tasks like classification, regression, and clustering across various domains.