



Unsupervised Learning
We had hubris a couple years ago, thinking you could create accurate machine learning (ML) models completely unsupervised. Turns out, we do need some human supervision—just enough human knowledge to train the model properly. The trick is to minimize that human supervision and use machine learning itself to alleviate the “grunge work”. In other words, we can automate the bulk of the process with data pre-processing, labeling, and model calibration.
You want to have some ground truth in the form of pre-labeled examples for each class. You could need as few as one or two per class, according to some companies in the category of few shot learning. But to the point of labels and human supervision, when you go completely unsupervised, you miss out on a lot of human knowledge. It all depends on the use case and the data itself, but we typically see great results with roughly 100 per class. With Jaxon, you can quickly get guidance on how much really is needed to hit your desired performance metric.
Writing Heuristics
A great way to encapsulate human knowledge about a domain is to write heuristics. Marrying these heuristics into an ensemble of classical and deep neural models usually should be done with more sophistication than just a majority vote. With innovations like Snorkel coming out of Stanford, intelligent aggregation and the ability to abstain from even using a heuristic is now possible. Here’s their definition of the new category of ML called Weak Supervision:
“Weak supervision is a branch of machine learning where noisy, limited, or imprecise sources are used to provide supervision signal for labeling large amounts of training data in a supervised learning setting.”
Heuristics are a powerful way to fill in gaps of coverage for a model. We recommend feeding data into Jaxon and seeing how the trained model performs. Maybe it’s good enough without any further human time. Likely, heuristics can give lift to areas where the classical and neural models are performing subpar.
Vetting Synthetically Labeled Data
You can also use Jaxon to vet synthetically labeled data. Using a small amount of pre-labeled examples, Jaxon bootstraps an ensemble that serves as a labeler. From there, users label their raw (unlabeled) examples. The cycle continues as a new dataset in Jaxon and, through a vetting portal, users review the labels and either agree or disagree with the label. Simple as that. Going forward, we recommend sampling 500 examples (regardless of corpus size), which typically takes a couple hours to vet.
Vetted labeled examples (what we call gold) for training, testing, and calibrating are key for hitting high F1 scores with minimal human time. They also prove useful for noisy data (which, let’s be honest, is the norm, especially with natural language data sources). This gold amplifies human knowledge and drastically reduces the need to manually label tons of examples.
With (Just Enough!) Human Supervision
Look at this before and after for a model we recently helped create:
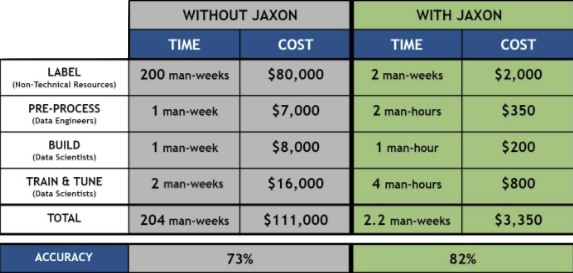
Not only did Jaxon save 90% of the time that would otherwise have been spent, it also increased the model’s accuracy by 9%.
– Scott Cohen, CEO