



The Gold Standard of Linguistics
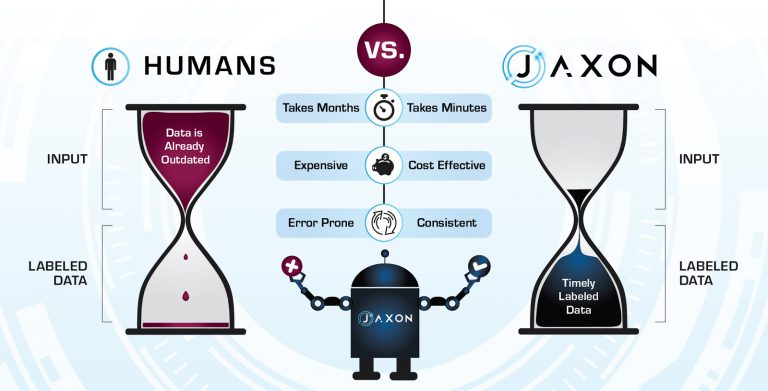
Why would you use AI to label data? Long story short, humans are slow. When humans label text—for example, reading a tweet and deciding if it demonstrates positive or negative sentiment—the whole process takes at least 10 seconds. However, a machine can make the same judgement in milliseconds.
On top of that, humans are also inconsistent and easily influenced. Consider studies of eyewitness accounts that demonstrate that memory is not to be trusted. After DNA evidence was introduced, 71% of convictions based on eyewitness testimony alone were overturned. Psychologists have shown that through suggestion, partial recall of false memories can be easily induced in almost half of study participants. Psychologists have been demonstrating for years how easy it is to influence participant responses. They could be affected by anything from text they have previously read, conversations the experimenters or other participants prior to the experiment, to unintentional nonverbal communication by the experimenters. Humans, all of us, are just not impartial judges.
The Many Standards of Linguistics
In linguistics, a native speaker’s judgements about a sentence are considered ground truth, a gold standard. For example, which of these sentences would you say are grammatically correct?
- After all this dry weather, the car needs washed.
- After all this dry weather, the car needs to be washed.
Most native English speakers would label 1 as incorrect and 2 as correct, but if you’re from Pittsburgh, 1 is technically also correct. So if you ask two people from different regions to label these sentences, you may get opposite results. How do you get your ground truth now?
Things get even trickier when people make judgements about something like sentiment. As an example, consider if the sentiments of these sentences are positive or negative.
- These Nike kicks I just got are bad.
- I’m quite chuffed with my new Adidas trainers.
- Just bought these new shoes. They’re fine.
Depending on factors like location, race, age, or socioeconomic status, each of these examples could be judged as positive or negative—and both would be correct. There’s no way to know which is right without also knowing context or the writer’s intent. As it turns out, the ‘truth’ really is subjective.
To combat this, companies generally solicit at least three different human judgments per label. With inconsistent labeling or unclear, ambiguous tasks, more humans will be needed for every label produced to train these applications. Nothing prevents labelers from being influenced by past labels, their state of mind, or where they are.
The Time Problem
Now consider that AI applications need anywhere from several hundred thousand to millions (and sometimes even billions!) of examples for adequate training data, and that each human judgement will cost upwards of 10 cents depending on the examples being judged. That price, of course, assumes you don’t need an expert to make the judgements, which will cost a LOT more—by several orders of magnitude. That’s money wasted doing a single task several times over to make sure it’s adequate.
After businesses have gone through this weeks-to-months-long process, they tend to assume that their labels are ground truth and ready to be given to AI applications. The labels are 100% accurate, or should be, right? But this is not the case. A study at Stanford found that human-labeled data from paid platforms like MTurk is only about 87% accurate. That’s not exactly the ‘ground truth’ businesses are paying for.
Because labeled data takes so long to arrive, once it finally reaches your hands, its useful lifespan may be short—or already over. Language changes constantly, and companies and industries are frequently shifting focus and direction. Then what happens when a chatbot needs to learn brand new marketing or domain-specific terms? Or a sentiment analysis engine encounters new slang like “poggers” and “zoomer”? Should companies go through the entire, expensive weeks- to months-long labeling process all over again or settle for out-of-date, low-performing AI?
How to Use AI to Label Data
These limitations are just some of the reasons why using AI to label data and train other AI applications simply makes sense. The process of generating large training sets takes minutes to hours, enables models to be updated and changed as frequently as necessary, and lets companies aim beyond ‘good enough’. They can have the most up-to-date models all the time no matter how fast language, marketing, or focus changes.
As AI itself, Jaxon is an impartial labeler that is not susceptible to outside influence. And best of all, Jaxon understands your company’s domain-specific terminology, regardless of how unusual or nuanced, because it learns from your data.
– Charlotte Ruth, Director of Capture Management