At Jaxon, we believe flexibility is key to building trustworthy AI workflows. Whether you’re analyzing financial compliance policies, assisting with Section 8 housing eligibility determinations, or supporting mission-critical decision-making in defense environments, the model behind the scenes matters. That’s why Jaxon supports a range of models, so you can optimize for speed, reasoning depth, or cost, depending on the task.
What Models Does Jaxon Support?
A few standout models we support:
- openai/GPT-5
- openai/o3-mini
- openai/o4-mini
- openai/o3
- openai/chat (GPT-4o)
- watsonx_text/granite-13b-instruct-v2
- watsonx_text/mixtral-8x7b-instruct-v01
- watsonx_text/meta-llama/llama-3-2-3b-instruct

Let’s dig into what makes the newer OpenAI models worth your attention—and how they compare to the rest.
| Model | Best For | Strengths | Tips from the Jaxon CTO |
|---|---|---|---|
| openai/GPT-5 | Advanced general reasoning & multimodal/agentic workflows | State-of-the-art planning, self-correction, reliable tool use, strong code & writing | Use when correctness really matters; pair with o4-mini for high-volume tasks |
| openai/o3 | Complex, multi-step reasoning | High intelligence, strong performance on nuanced tasks | My go-to for heavy lifting |
| openai/o4-mini | Fast, cost-effective reasoning | Excellent at math, code, visual tasks; great non-STEM performance | Ideal for high-volume use |
| openai/o3-mini | Balanced workloads | ~⅓ the cost of o1-mini, nearly as smart as o4-mini | Decently fast, solid fallback if you want a cheaper option than o4-mini |
| openai/o1-mini | Legacy use or baseline benchmarks | First-gen "mini" model | Largely deprecated, you deserve better |
| openai/chat (GPT-4o) | Generalist applications | Conversational, multimodal support | Slower, less capable, and more expensive than either of the mini models |
| watsonx_text/granite-13b-instruct-v2 | General reasoning | Customer sentiment, summarization, and financial text analysis | Reliable mid-size model |
| watsonx_text/mixtral-8x7b-instruct-v01 | Versatile, open-weight needs | Efficient MoE architecture with strong multilingual support | Great performance-to-cost ratio |
| watsonx_text/meta-llama/llama-3-2-3b-instruct | Lightweight inference | Small footprint, fast responses | Best for constrained settings |
CTO Picks, Passes & Pro Tips
- Pick: Use o4-mini for most tasks—it’s fast, cheap, and surprisingly smart.
- Pass: Skip o1-mini and chat unless you have legacy reasons.
Pro Tip: Keep watsonx models in play if you’re optimizing for data governance or using hybrid clouds.
How We Evaluate Models at Jaxon
We don’t just rely on provider benchmarks—we run our own. Every model we support is tested against a growing library of domain-specific tasks, from financial policy QA and regulatory document analysis to structured reasoning in defense and housing contexts. Our internal benchmarks go beyond STEM and trivia to assess how well a model performs with guardrails under real-world constraints. That’s how we determine when a model is “good enough”—and when it’s not.
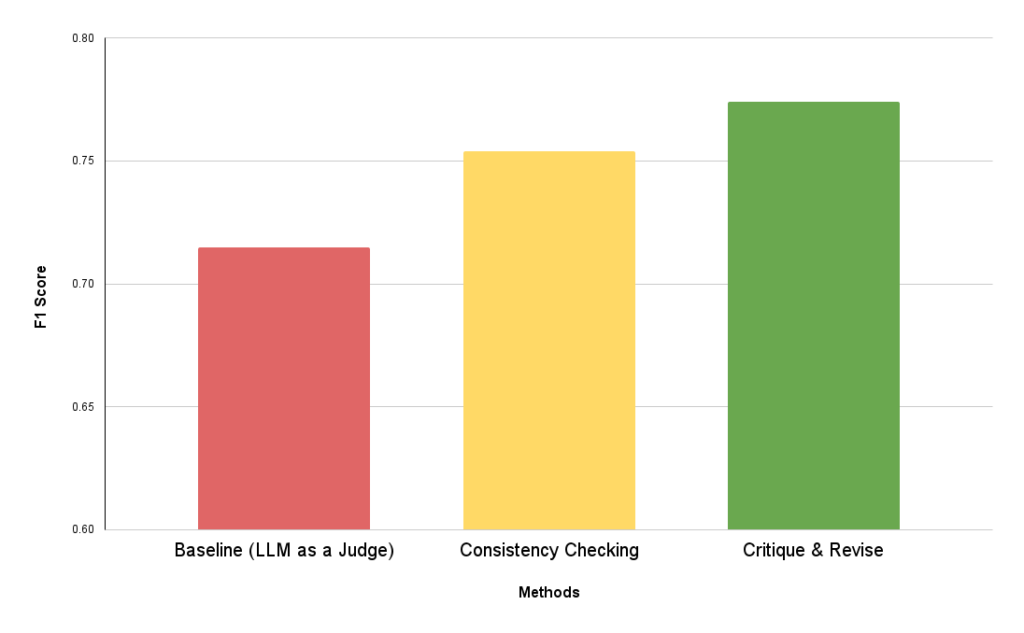
We recently ran a benchmark using GPT-4o as the base model and layered two Jaxon guardrails—Consistency Checking and Critique & Revise—on top. These guardrails, powered by DSAIL, evaluated how reliably the model could detect hallucinations and correct itself.
Using verified QA pairs from FinanceBench, we compared baseline performance to Jaxon-augmented workflows. The result? Jaxon’s agentic methods boosted accuracy by 8.25%, with the Critique & Review workflow achieving an F1 score of 0.774 compared to 0.715 from a standard LLM-only evaluation.
That’s the difference between guessing and knowing.
Going Beyond the Model
Choosing the right LLM is just the beginning. What makes Jaxon different is what comes next: our smart, modular guardrails and the technology that brings them to life – DSAIL.
Our Domain-Specific AI Logic (DSAIL) converts natural language into machine-readable logic that can be evaluated using symbolic reasoning. It bridges the gap between generative output and verifiable truth—enabling Jaxon to detect hallucinations, enforce policy, and prove compliance across domains like finance, defense, and other regulated industries.
With Jaxon, you can:
- Select reasoning depth (low / medium / high) where supported (e.g., o3-mini)
- Set up critique-and-revise workflows that improve outputs before they’re returned
- Enforce guardrails for policy alignment, factuality, and internal consistency
- Add optional human review checkpoints to flag or validate key decisions
- Use the dashboard to compare models and analyze output trends across tasks
And here’s the best part: DSAIL works with whatever model you’re already using. Whether you’re deploying o3, o4-mini, or a watsonx model, Jaxon can layer guardrails on top to detect hallucinations, enforce compliance, and deliver reliable outcomes across finance, defense, and other regulated domains.
Need help building guardrails for your AI project? Contact us!
– Danitra Campbell, Growth Advocate