



Benchmark

Jaxon has hit a major benchmark in its quest to minimize the amount of human-labeled examples needed to properly train machine learning models.
We came within points of hitting the same F1 accuracy scores as state-of-the-art models with just 20 human-labeled examples, versus the 25,000 needed prior.
Jaxon uses a mix of AI techniques to create training sets.
This experiment got the most lift from our unsupervised data augmentation, which supplements real data with synthetic data.
Results
Results are presented with the model along the x-axis and corresponding F1 score on the y-axis.
These F1 metric scores (accuracy measurements) are calculated by measuring the model’s predictions against a holdout dataset sliced off from the original dataset.
Model F1 Accuracy
for IMDb Sentiment Analysis
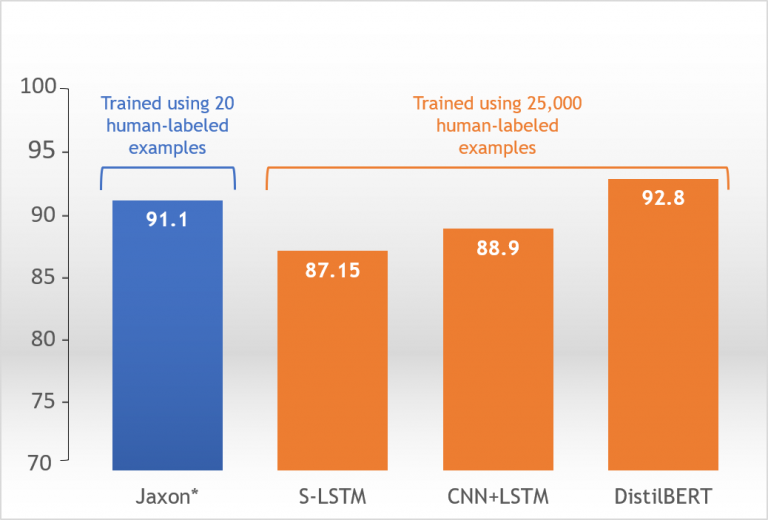
*Augmented DistilBERT using Jaxon’s synthetic data
Experiments
Experiments were conducted using the IMDb dataset described to the right. Labels were stripped from the dataset, and the now-unlabeled dataset was uploaded into the Jaxon platform. Examples were classified within the platform as either a positive or negative review.
20 examples were manually labeled within the Jaxon platform, which took about half an hour. These 20 labeled examples and the rest of the unlabeled dataset (less 25% held out for testing) were then used to train an augmented DistilBERT model leveraging Jaxon’s unsupervised data augmentation technology.
The IMDb Dataset
The IMDb dataset is most commonly used to train models in order to classify the polarity of a given text. This data is comprised of 100,000 total movie review examples. Of these examples, 25,000 are labeled and 75,000 are unlabeled. The 25,000 labeled examples are classified as either a positive or negative review with a 50/50 split between the two (12,500 positive and 12,500 negative).