Detect Errors & Evaluate Models (DEEM)
Validate AI against your standards—not generic benchmarks. DEEM enables teams to create custom evaluation specifications, define what success looks like, and continuously validate performance against those standards.
You can't trust what you can't formally define.
DEEM allows teams to articulate exactly what success looks like in their domain — from structured data extraction to safe fallback behavior.
Specify Before You Trust
Define exactly what constitutes valid model output before a model is ever tested.
Assess Consistency
Detect drift and evaluate model behavior over time across semantically equivalent inputs.
Operationalize Your Standards
Turn formal definitions into automated, auditable, continuous monitoring.

Powered by AISL
AI Specification Language (AISL) is a formal language designed to define the operational boundaries and correctness criteria for AI systems. DEEM is built on AISL — creating an auditable standard that travels with your system from development through deployment, catching silent failures before they become mission risks.
WHY DEEM?
DEEM adapts to your mission—not the other way around. Teams can create custom evaluation specifications tailored to their mission requirements, so your AI is measured against the standards that actually matter to your operation—not generic benchmarks designed for someone else’s use case.
.
AISL works in tandem with DSAIL (Domain-Specific AI Language), Jaxon’s verification and validation engine. Where AISL defines what correct behavior looks like, DSAIL provides formal, proof-based guarantees that AI outputs meet your operational standards.
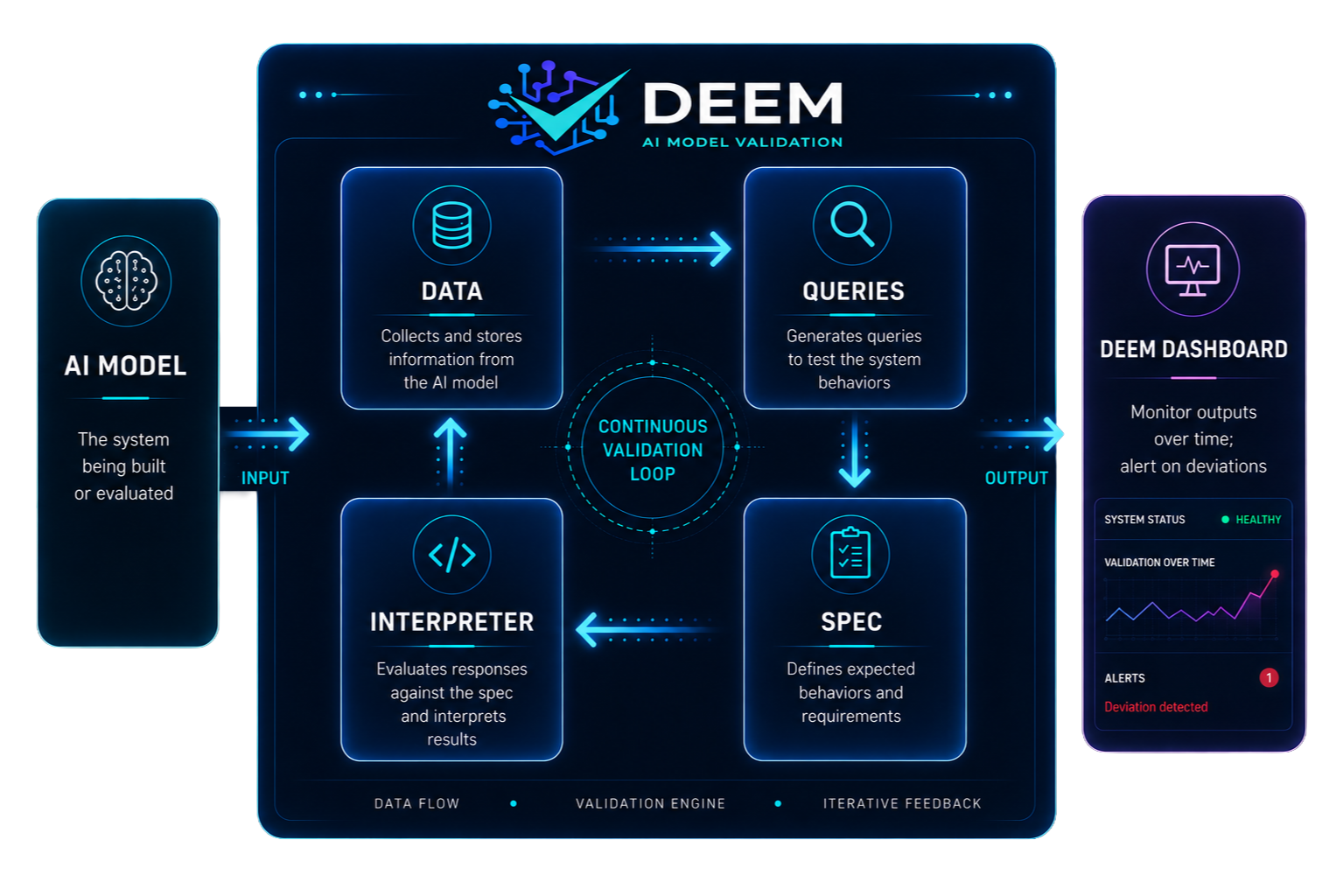
How DEEM Works
From Spec to Signal
DEEM identifies when outputs fall outside formally defined compliance boundaries and signals when intervention is required.
Write your spec
Use AISL to specify valid outputs, error conditions, and acceptable behaviors for your AI system.
Run inputs through the model
DEEM feeds queries to the target AI model and collects outputs through the continuous validation loop.
Interpreter evaluates responses
The AISL interpreter checks model outputs against your spec, applying your metrics and balancing conflicting priorities.
Dashboard alerts on deviation
DEEM monitors outputs over time and alerts your team when behavior falls outside compliance boundaries — prompting recertification.
Real-World Example
DEEM in Action
Most evaluation tools test against fixed benchmarks. DEEM lets you define your own. Create and update custom specifications as your mission, environment, and success criteria change.
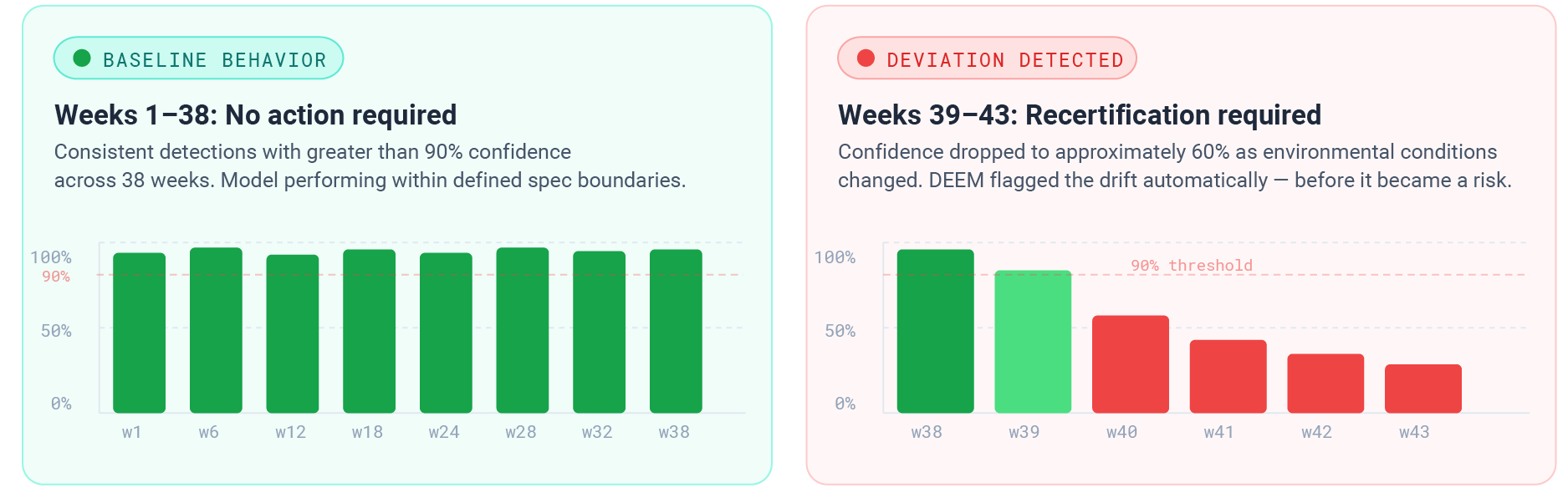
Unlike off-the-shelf evaluation tools, DEEM lets teams define custom evaluation specifications using AISL. Those specifications act as operational contracts for AI systems. When performance falls outside the defined boundaries—like confidence dropping below a required threshold—DEEM automatically flags the deviation before it becomes a mission risk.
WHY DEEM
Built for High-Stakes AI
Unlike rule-of-thumb metrics, DEEM creates an auditable standard that travels with your system from development through deployment.
Custom definitions of success
Define acceptable output even when task-specific. DEEM enables stable, repeatable definitions of performance across diverse models and tasks.
Consistency Checking
Evaluate whether semantically equivalent prompts produce aligned responses. Detect instability, uncertainty, and sensitivity to phrasing before deployment.
System-level drift detection
Get alerted automatically when AI behavior no longer aligns with your defined standards. DEEM prompts recertification the moment performance degrades.
Side-by-Side Benchmarking
Compare models and monitor iterative improvements. Evaluate different prompting strategies, model variants, or fine-tuning recipes against your formal specs simultaneously.
Continuous Validation
Detect drifts, failures, and quality issues automatically. DEEM monitors production behavior over time and signals when outputs fall outside your compliance boundaries.
Automated quality assurance
Automates regression analysis, consistency checking, and tracking performance improvement or degradation over time — so manual review becomes a choice, not a requirement.
LLM-Specific Capability
LLM Consistency Checking
DEEM assesses LLM reliability by measuring how stable a model’s responses are when presented with different phrasings of the same semantically equivalent input.
Consistent answers suggest the underlying knowledge or reasoning is well-grounded. Divergent responses may signal uncertainty, sensitivity to surface phrasing, or a lack of contextual understanding.
All inputs are run through the target LLM, and a consistency metric is applied to determine whether outputs remain aligned across different formulations.
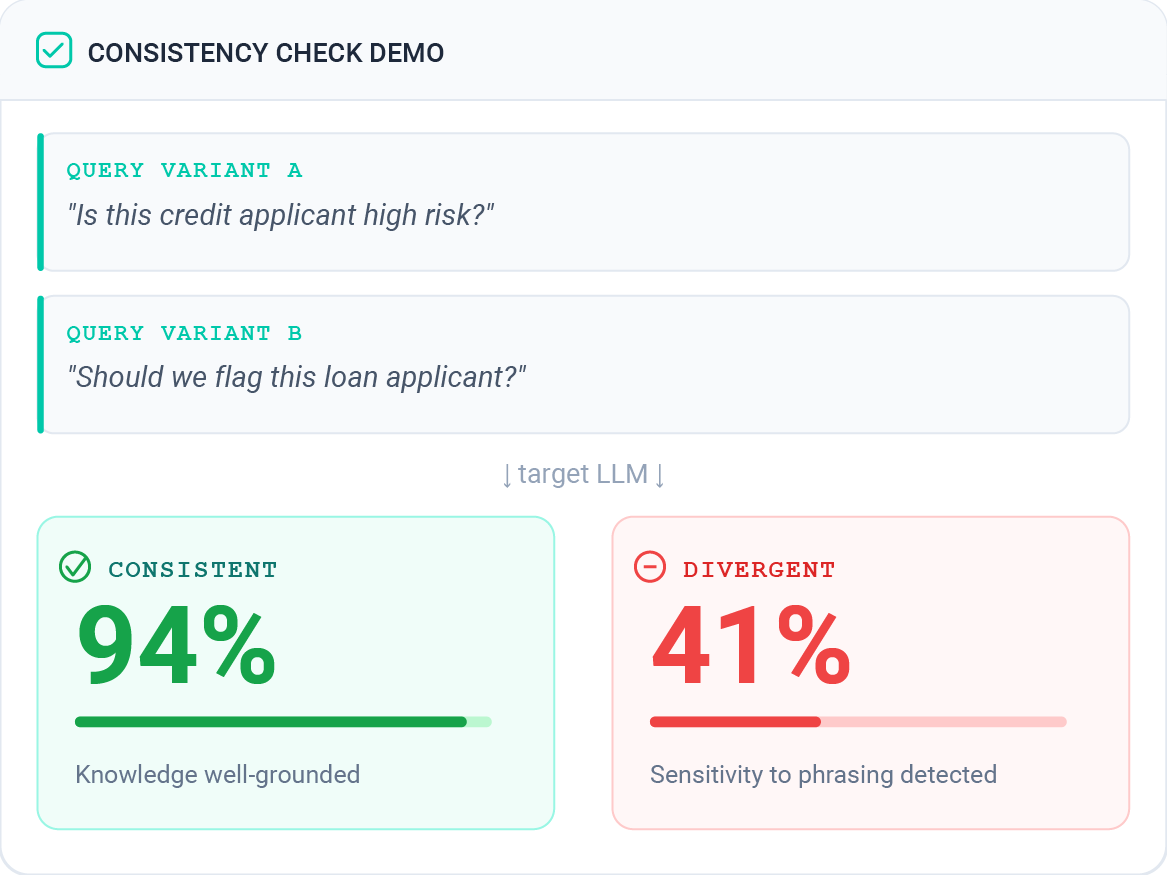
Asking the same question in two different ways
Get Started
See DEEM in action
Our team will walk you through a demo built for your use case.