Why the Industry's Guardrails Fall Short and How Jaxon Is Redefining What Trust in AI Really Means
In the rush to make large language models safe, trustworthy, and enterprise-ready, the word guardrail has lost its meaning.
Today, most AI “guardrails” focus on surface-level safety, blocking profanity, removing PII, or wrapping prompts. These are useful and often necessary. But they aren’t enough. In high-stakes domains like finance or healthcare, AI must do more than avoid mistakes—it has to prove it’s right.
And hey, we support the basics, too. Need profanity filters? PII redaction? Prompt injection defense? Jaxon can help. But we don’t stop there. Where today’s guardrails check for risk, we check for compliance—the difference between avoiding trouble and proving you’re right.
The Case of Maya at Cleric, LLC
Maya is the Head of Compliance at Cleric, a fictional fintech startup building an AI-powered investment assistant. The pitch? A friendly LLM-based chatbot that helps customers navigate everything from ETFs to IRAs to market trends.
But Maya’s no rookie. She’s worked in regulated spaces before. She knows what happens when compliance is an afterthought—especially when AI is involved.
When Cleric rolls out its first LLM, Maya insists on “guardrails.” The team wires up off-the-shelf tools to keep the AI in check.

- Profanity filter
- PII redaction
- Tone smoothing
- Keyword bans
At first glance, these filters do their job. They block inappropriate content and sanitize tone – exactly what they were designed to do. But when Maya starts reviewing transcripts, she sees the limitations.
The Illusion of Safety
That’s when she finds the AI confidently making claims like:
“This ETF guarantees a 10% return.”
“You can deduct that from your taxes without any issue.”
“You won’t owe capital gains if you sell this year.”
None of those statements are technically true. Some are legally risky.
All of them slipped past the guardrails.
Why? Most industry guardrails today operate on word matching. They’re great for catching known risks, but they don’t evaluate the meaning of what’s said. That gap is where compliance issues sneak in.
Maya wanted compliance. What she got was a content filter doing its best to act compliant.
Let’s Talk About Real Guardrails
Our approach is powered by Domain-Specific AI Logic (DSAIL), a neurosymbolic engine that turns AI outputs into structured logic and tests them against real rules. It’s the natural evolution of today’s guardrails – from surface-level filters to deeper checks rooted in policy and proof.
Instead of asking the LLM for an answer and then scanning it for problems, our platform uses the LLM to extract the key facts behind its response. These are the specific claims the model is making. We convert those claims into structured data that can be tested against real rules.
Then we run those facts through a set of formal policy rules, built on a domain-specific language (DSL) that captures real compliance logic. The rules aren’t scanning for banned words, they’re testing whether the answer meets specific requirements:
- Was the risk disclosure included?
- Did the bot mention limitations for the asset class?
- Was the recommendation appropriate for the user’s stated profile?
The output isn’t a vibe. It’s a provable score. And if something goes wrong, we can explain why, in terms a compliance officer—or a regulator—will understand.
Enter P.R.O.V.E. – Jaxon’s Trust Workflow™
This is the backbone of our approach to AI assurance:
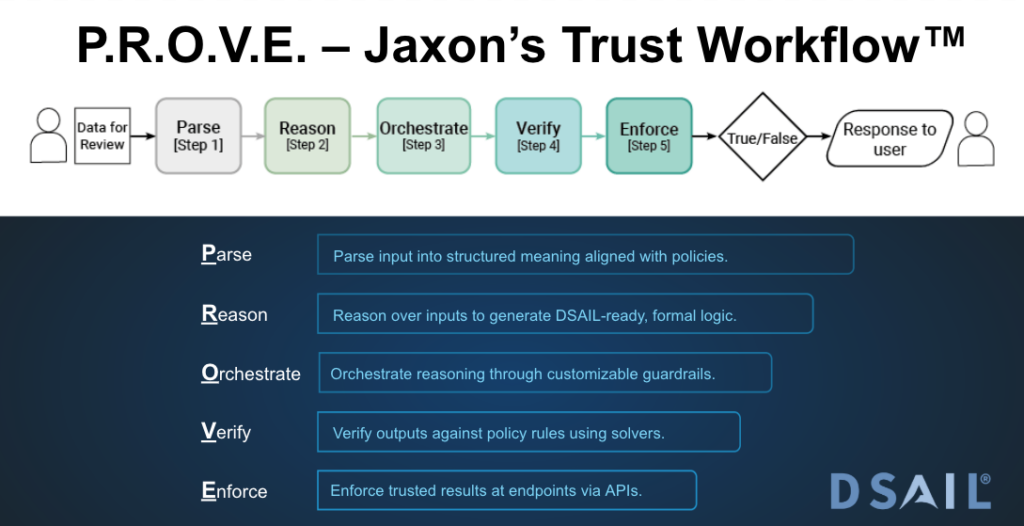
It’s not just a clever acronym. It’s how we deliver provable compliance at runtime, with explanations, traceability, and rigor baked in.
The Difference That Matters
Most “guardrails” ask:
“Did the AI say something we don’t like?”
We ask:
“Can we prove the AI followed the rules?”
This distinction changes how trust, compliance, and reliability are engineered into AI systems.
So No, We're Not Just a Guardrail Company
We can help your AI stay polite, but we also help it stay provably correct.
We’re here to make it provable.
So next time someone says, “Don’t worry, we’ve added guardrails,” it’s worth asking:
Are they just filtering outputs?
Or enforcing rules?
Maya—and Cleric—aren’t real.
But the risks they faced? Absolutely are.
And your solution better know the difference.